결론 :
그리드 서치란 하이퍼파라미터의 범위를 설정해두면
최적의 모델을 알아서 찾아서 반환해주는 그런것이다.
용어 정리
epoch
- 한 번의 epoch는 신경망에서 전체 데이터 셋에 대해 forward pass/backward pass 과정을 거친 것을 말함. 즉, 전체 데이터 셋에 대해 한 번 학습을 완료한 상태
batch_size
메모리의 한계와 속도 저하 때문에 대부분의 경우에는 한 번의 epoch에서 모든 데이터를 한꺼번에 집어넣을 수는 없습니다. 그래서 데이터를 나누어서 주게 되는데 이때 몇 번 나누어서 주는가를 iteration, 각 iteration마다 주는 데이터 사이즈를 batch size라고 합니다.
출처: https://www.slideshare.net/w0ong/ss-82372826
GridSearch 를 이용한, 최적의 하이퍼 파라미터 찾기
# Tuning the ANN
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import GridSearchCV
from keras.models import Sequential
from keras.layers import Dense
X_train[ 0, :] # 이 데이터(첫번째 데이터)가 들어온다고 가정하고 아래의 함수를 생성
# 텐서플로우로 그리드 서치 하기 위해서
# 1. 모델링하는 함수를 만든다.
# 매번 다시하기 귀찮기 때문. (위에서 만든것을 하나로 합친것과 같다.)
def build_model(optimizer):
# 모델링
model = Sequential() # 깡통생성
model.add( Dense( units = 6, activation= 'relu', input_shape=(11, ) )) # 깡통에 담음 , 노드 6개, 배출 == activation ,input_sahpe 1차원으로 만들고 11열을 썻다.
model.add( Dense( units = 8, activation= 'relu' )) # 두번째 숨겨진 레이어 생성
model.add( Dense( units = 1, activation= 'sigmoid' )) # 출력 레이어 생성
model.compile(optimizer=optimizer, loss= 'binary_crossentropy', metrics=['accuracy']) # 변수로 받아 옵티마이저를 변경
return modelmodel = build_model('adam') # 옵티마이저 'adam' 으로 테스트# 2. 그리드 서치를 위해서, 그리드서치용 클래서파이러를 만든다.
# 그리드서치란 == 하나씩 넣어서 좋은거 가져와바라 이런뜻.
# 옵티마이저 조합도 알아서 다한다.
model = KerasClassifier(build_fn = build_model) # build_fn = 위에서만든모델 변수를 넣음.
my_pram = {'batch_size': [10,20,32], 'epochs': [20,30,50], 'optimizer': ['adam','rmsprop'] } # 어떤조합으로 하고싶은데? (하이퍼파라미터 설정), 여기선 3*3*2 = 18 개의 조합으로 만든다.grid = GridSearchCV(estimator = model, param_grid= my_pram, scoring='accuracy') # estimator == 만든인공지능 , 내가만든 조합을 넣는다 param_grid = , scoring == 분류의 문제는 정확도가 중요함.grid.fit(X_train, y_train) # 이로써 자동으로 최적화 값을 찾아주는것을 완성.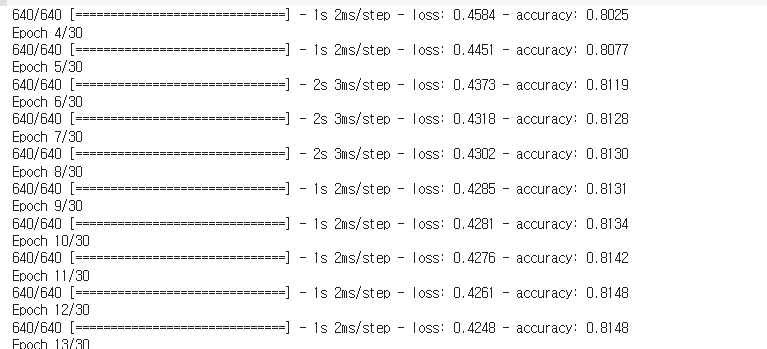

grid.best_params_ # 제일좋은 파라미터는 무엇이엇냐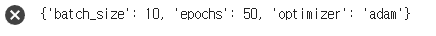
grid.best_score_ # 학습데이터로 했을때 베스트 점수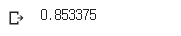
best_model = grid.best_estimator_ # 베스트 인공지능을 저장best_model.predict(X_test) # 예측해본다. # 케스트클래스파이어
y_pred = best_model.predict(X_test)best_model.predict_proba(X_test) # proba == 확률로 나온다 # 1에 가까울수록 0일확률, 0에 가까울수록 1일확률
confusion_matrix(y_test, y_pred)
accuracy_score(y_test, y_pred)
'DataScience > TensorFlow[ANN]' 카테고리의 다른 글
| 딥러닝 텐서플로우 leaning rate를 옵티마이저에서 셋팅, 밸리데이션 데이터란 무엇이고 사용법,EarlyStopping 라이브러리 사용법 (0) | 2022.12.28 |
|---|---|
| 딥러닝 regression 문제, epoch_history, loss(경사)를 눈으로 확인 (오차가 더 떨어질지 보는것) (0) | 2022.12.28 |
| 딥러닝 텐서플로우 리그레션(regression) 문제 모델링 하는 방법 (0) | 2022.12.28 |
| 딥러닝 ANN개념 정리 요약 (0) | 2022.12.27 |
| 딥러닝 텐서플로우에서 학습시 epoch 와 batch_size 에 대한 설명, dummy variable trap, 분류의 문제 모델링 하는 방법, 실무 예시 (0) | 2022.12.27 |
